
If a three-dimensional space is translated into a pattern of sounds, could one use it to gain object recognition without sight?
That's the question the SNAP project (Sightless Navigation and Perception) is working to answer. The question remains open, but the project is taking on steam, winning funding from Hackaday and going in for a second year of development by senior students at the University of Idaho.
Grab a pair of headphones and watch this video. Then close your eyes during the demos and see what you think.
Current demonstration of the SNAP hardware. The overlay shows the depth map output of the RealSense R200 camera.
The project creator, Dan Schneider, and I have known each other for a long time. We both attended the University of Idaho, and also played in a band together (one of the songs is used as backing to the video). Dan has been periodically calling me up to discuss and explore concepts of this project, so I've been curious from the beginning. I recently called him up for an interview and share his story here. Enjoy!
Project Inception, University of Idaho Capstone, 2016--2017
I asked Dan how he got into all of this. It turns out the question is pretty common for him.
"I had an innate interest in blindness because my dog was blind, yet she could find her way around. After I became an engineer and learned about a lot of technology, I realized there's a lot of room for improvement.
At some point I learned about blind people who could echo-locate, and even ride a bicycle with clicking sounds. When I became comfortable with range sensors I realized I could apply them towards mapping the environment and translating that info into audio."
The project was too big for the free time available. The idea was pitched to our alma mater and accepted as an engineering capstone project with basically only the hardware cost to consider.
Focusing on what works and is cheap, the team wrote a game that was programmed in 3D, but rendered in audio for the players.
Parts of the game:
The game works by rendering a simple 3D space, but instead of picture output, the view is converted to depth map. The Intel® RealSense™ R200 camera also produces depth map information, so it was a good stepping stone. The view, as the depth map, is grabbed and sent to a back end that uses OpenAL to generate waveforms with different tone and spacial parameters.
They did well and left some resources. Development gets pretty hairy sometimes, so I wouldn't try to run the GitHub repository...wait for the next capstone team to finish. The goal was to determine if this is a feasible venture.
The Wearable Demo

Current implementation of the design
Hardware and Software
To make a wearable demo out of the design team's deliverables, the back end was extracted, run on an Aaeon UP board and connected to the output of an Intel RealSense R200 camera. The UP board is an atom-based mini-computer, and the R200 is an IR camera with depth-map output.
I asked Dan if he thought the RealSense was a good product.
"Absolutely. It was everything we thought it would be and nothing we thought it wouldn't."
Looks like they did their research!
"The Aaeon UP board is fast enough to handle the significant amount of processing we have to do. It could be done with Raspberry Pi, but the UP board was bundled with the R200."
He's running C code on the Aaeon, and it's actually quite simple compared with the capstone research platform. Have a look at the main.cpp file he's using.
Algorithm
What you're hearing is a set of frequency generators sweeping around. There are audio parameters that can be modified, and a set of 3D points that are mapped to those audio parameters. The goal of the next capstone team is to figure out what the best mapping is. For the demo, amplitude, frequency and stereo separation is used. A spherical coordinate system of radius, theta and gamma is obtained from the input device.
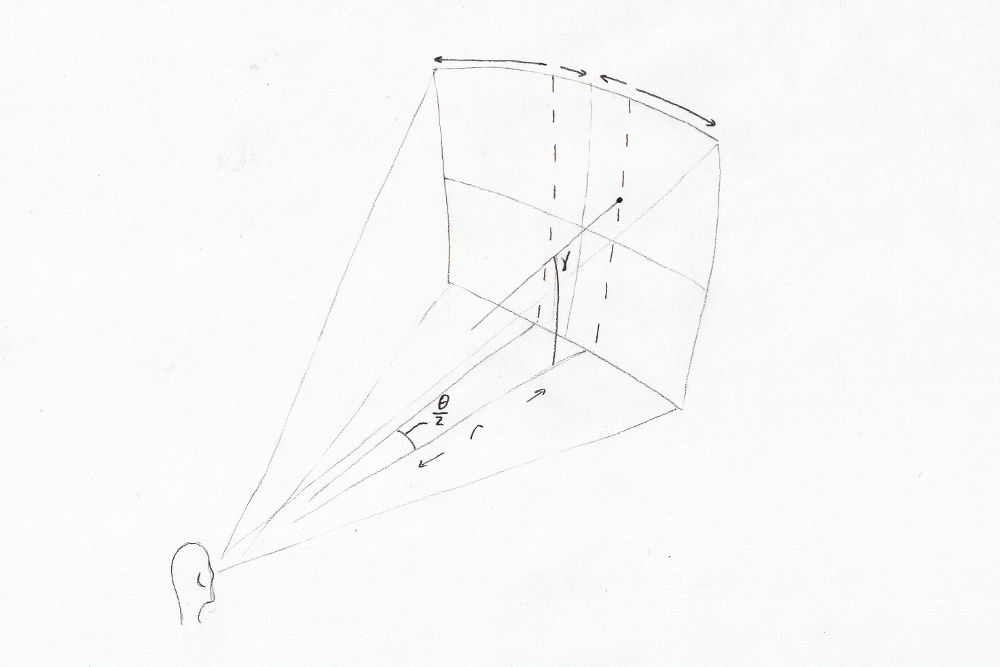
The coordinate system of SNAP
I asked Dan to clarify how the mapping works so we could talk about it.
He specified:
- Horizontal (theta) maps to stereo separation (interaural time/level difference)
- Vertical (gamma) maps to frequency, with high frequencies on top
- Distance (radius) maps to amplitude.
He went on to describe the basic system:
"Because we can't 'display' all of the audio sources at the same time we are scanning. We produce vertical scan lines, two at a time, that sweep from the center (in front) outward to the edge of the field of view. Then they bounce back in.
There are 16 audio sources playing at any given moment (for vertical resolution). I have increased that number to 30, but the resolution of the depth map is poor enough that there's too much overlap and it has trouble handling it.
There are 16 horizontal steps at 2ms per horizontal step. A resolution of 32 on the theta axis.
Right now we grab a region of interest and average the shade of the depth map and map it to a number. Then we map the number to range of frequencies. My favorite range is 200Hz up to 1.5kHz."
Theory
Dan was keen to note that this isn't the final solution, just what is in the demo. Dan and I have always disagreed on what parameters should be mapped to what axes, and always seem to land on the fact that neither of us know. Maybe there should be a single sound generator for each pixel, or region of interests. Or, vary the wave shape as the sweep occurs. Maybe the ear could pick out timbre, and you could have a different symphony instrument sound for different heights.
"Dan, what's next for the project?"
"I would prefer to use pitch to map depth and use frequency or amplitude modulation for the gamma axis, which we haven't talked about yet. We have plans to go through a whole series of experimentation to find out what would be the most effective, easy to listen to, and least distracting.
We'll produce a fully featured simulator that is ready to download and install by anyone and everyone. That is the entirety of the senior design project.
The purpose of the simulator is to provide a test bed for experimental feedback parameters in which the user can use the audio feedback to play a video game. We're coding experiments into that software so that users have the option of participating in studies. In the study they would complete a course and send back anonymous stats to give us information about which frequency and waveform options are easier to learn and use."
He stressed that not distracting regular hearing is key in all of this. Even if it paints a perfect picture, a solution that overtakes the sense of hearing isn't a very good one.
Thinking about the future I went into the weird questions. "Do you think it's possible for the brain to transform this data into mental shapes with enough use?"
"A tree looks like a line and a boulder like a ball, so yeah, I do think you can tell the difference between tall and narrow, or short and wide easily.
Achieving advance shape recognition --- if square, triangular or round --- requires more resolution that we're currently getting, but with the properly tuned feedback (audio generated from 3D data) it is definitately possible once we've established the best frequencies and waveforms."
"And what's your goal for resolution?"
"Typical human hearing is capable of 1.5deg angular resolution (by interaural time/level difference). If we are to follow standard sampling rules, we want to be approximately half that. We need to hit 0.75 degrees to achieve max resolution. Vertical is much more rough; most people can sense between 6 and 15 degrees resolution."
So I hit him with the big question. "Is it possible to gain a 3D perception with an apparatus like this?"
"I do think it's possible, and this is the biggest point of contention on the project as far as human capability is concerned. We know that humans are capable of perfect pitch, meaning they can detect a particular frequency and recognize it without a reference point. We know that humans have separate portions of their brain devoted to individual frequencies allowing us to hear multiple frequencies and process that information in parallel. We also know that humans can recognize unique waveforms just as you can parse an individual instrument from an orchestra or symphony. Each of those things that we can do, however, we tend to only do a few at a time. So the question really is not whether or not we will be able to use the information we're given, but if we can use enough of it at once to really make sense of our surroundings. Following the case study of people who use echolocation, I think it is apparent that they detect more than one object per click. And, doing so is evidence that we will be capable of utilizing a full sound field as would be necessary to archive high-resolution spacial perception."
Well, I'm convinced. I'll be all ears next spring when the test platform is complete, and I can experiment with it myself!
Moving Forward
The project is currently all about determining if the brain can resolve acoustical data into spacial thoughts. With a successful capstone design complete, good reception and funding, and a new capstone project currently in progress, it's really coming along, and I'm excited to follow. But there's still a lot to consider.
The IR-based depth sensing is quite low range, and so the system is pretty disorienting outdoors. You have to get really close to a tree before realizing you're about to bonk your head. In the future, Dan would like to move to a stereoscopic camera system, or visual odometry for a better 3D input. With that, he can pick and choose what to render in the ears. Do you need to provide all the points in a plane for the brain to comprehend it? It might be better to throttle audio signals to reduce noise, and with a better 3D model this could be accomplished.

This render shows what the control unit may look like in the future. An easy thing to fit in a pocket.
Dan is a mechanical engineer, so he's also thinking about how to make the parts durable and comfortable. I'm eagerly awaiting requirements from the software development so I can do some hardware design. But all in due course --- all I know now is that the idea is great and the research is going well.
What do you think about this project? Let me know here, or post to Dan's Hackaday Project.
Stay intrigued,
Marshall
References
- main.cpp file for the demo video
- SNAP Hackaday project page
- 2016--17 Capstone project Wiki
- 2016--17 Capstone GitHub
- 2017--2018 Fall snapshot summary PDF
Thanks to Dan Schneider for spending the time with me, and thanks to:
- Colin Pate
- Matthew Daniel
- Eric Marsh
- John Snevily
...and to the currently-in-progress design team! Keep up the good work!







{kind=link}
Isn't this what Dare devil does??