We're back with our last installment (for now) in our machine learning series! We've talked about what it is, how it was developed and ways people are using it on a small scale, but now it's time to talk about the elephant in the room: how has it affected (and how will it continue to affect) the world we live in?

The Pervasiveness of Machine Learning
Machine learning has reached a level of ubiquity in our lives, so much so that it can be hard to remember a time before these optimized algorithms had their eyes on us everywhere we go. They're in our social media, our shopping, our internet browser, our healthcare, and more. As it becomes increasingly evident that the information age is giving way to the age of AI and ML, it's important we understand the role we all play in its development so we can be more knowledgeable and conscious of how we engage in this technology moving forward. This topic could be discussed for days, weeks, years, etc. so we don't have time for all the details, but I'll try my best to give you all an overview!
Everyday Applications
Scrolling on social media might feel like being a passive observer, but it's an interactive experience between you and the platform's algorithm. Take the TikTok algorithm for example; it logs not just your actual engagement with things by liking, commenting or sharing, but it also logs the amount of time you spend on each video it shows you. It knows which types of videos you'll scroll through and which type you'll stick with, and it uses that data to bin your behavior in with others who have similar patterns. This is a highly specific version of a recommendation system, which many believe TikTok has cracked the code on.
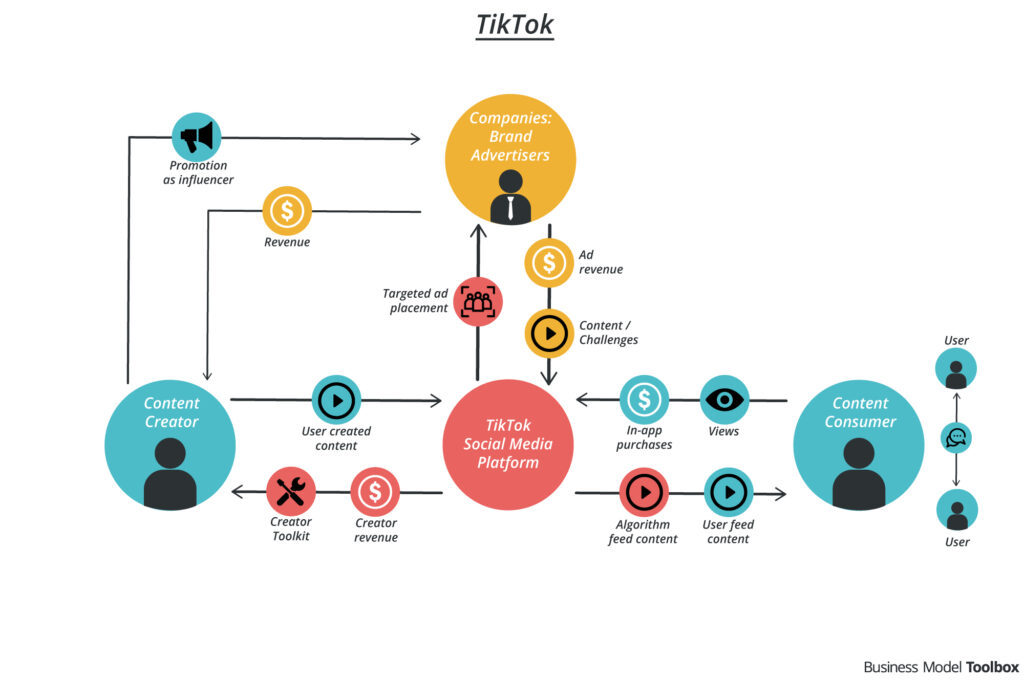
A recommendation system is an algorithm driven by user data that aims to use what it already knows about you to predict what you will consume in the future, whether that's products, entertainment, etc. They're used to improve consumer/user retention, increase sales, and form trends and habits within their customer base. Platforms use methods called collaborative filtering and content-based filtering to serve their users recommendations they'll be interested in.
Let's say you're watching Netflix. Netflix's algorithm knows your watch history, and it also knows all of its other users' watch history. If another user who watches and enjoys the same things you do also enjoyed a movie you haven't seen yet, Netflix will recommend that movie to you. This is an example of collaborative filtering. If you're attracted to movies with a certain genre, cast or director, Netflix will give you recommendations that have similar datapoints in those categories. This is an example of content based filtering.
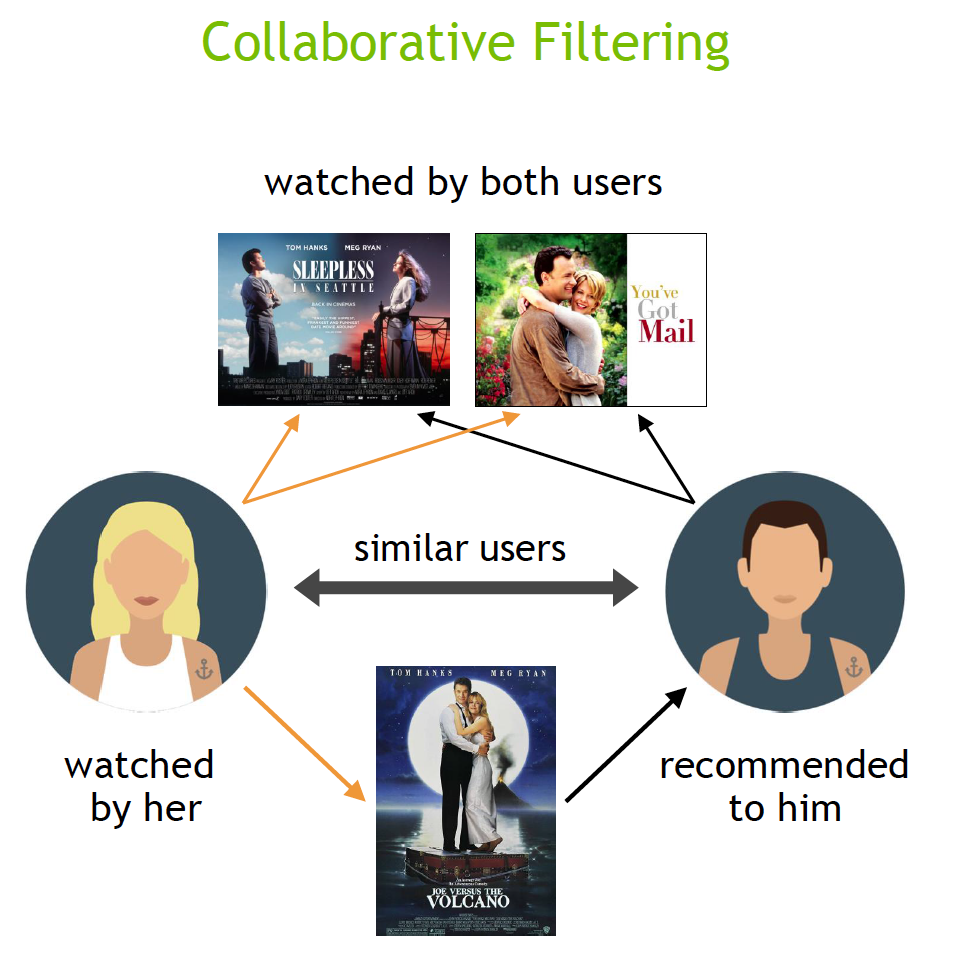
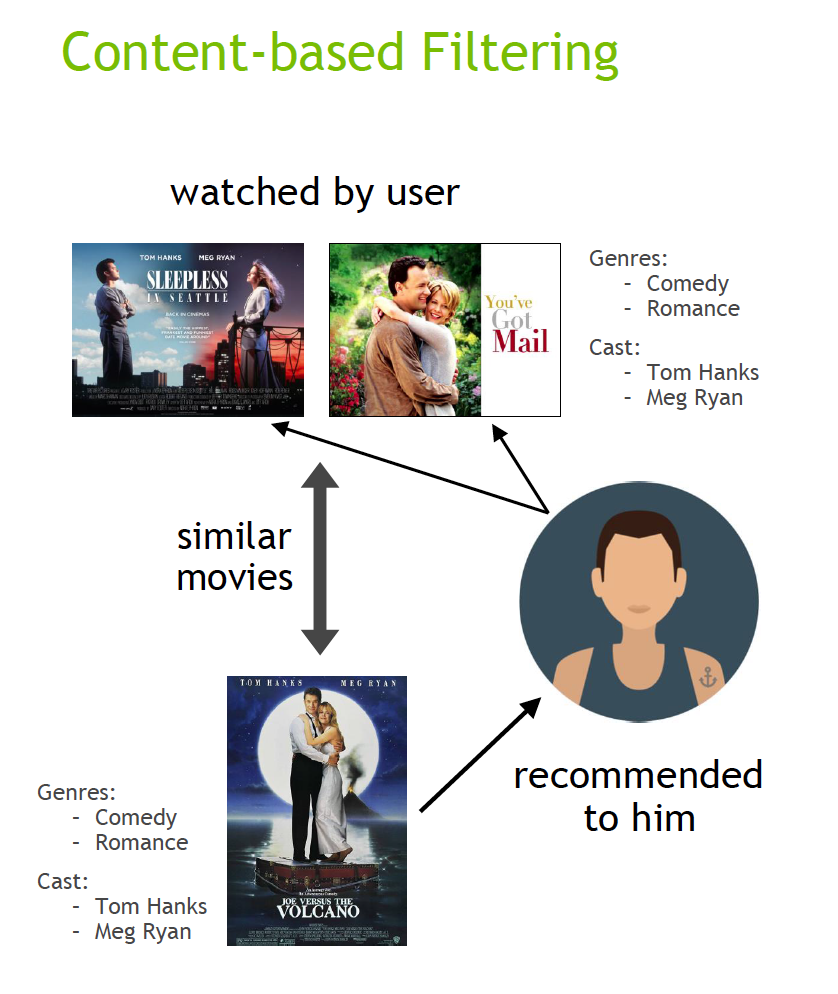
Source: NVIDIA
ML works in your life in a lot of ways you probably never stopped to think about. For example, it plays a crucial role in email filtering by automatically distinguishing legitimate emails from spam or unwanted messages. ML models are trained on extensive datasets that include a wide range of emails, learning patterns and features that differentiate spam or promotions from the rest of your inbox. These models extract information such as sender reputation, email content, metadata, and user interactions to categorize them.
As emails arrive in real-time, ML algorithms analyze their characteristics and assign probability scores, enabling rapid classification. User feedback further refines the filtering system, helping it adapt to evolving email patterns and user preferences. By leveraging ML, email services maintain clean and organized inboxes, safeguarding users from the deluge of unwanted content while ensuring essential emails reach their destination.
ML is also employed in navigation apps like Google Maps or Waze to enhance route planning and real-time guidance. These systems use ML algorithms to process vast amounts of data including traffic patterns, historical routes, and real-time GPS information. ML models can predict traffic congestion, estimate travel times, and suggest optimal routes by analyzing this data.
Apple Maps: Our artisanal cartographers hope you enjoy this pleasant journey. 28 min
— Tyler Nosenzo (@tnose14) January 24, 2018
Google Maps: Our algorithm has determined an optimal path for the most efficient route given current traffic conditions. 25 min
Waze: Drive through this dude's living room. 17 min
Even better, ML-driven navigation apps adapt to individual user behavior, learning preferred routes and destinations to provide personalized recommendations. By continuously updating and optimizing routes based on current conditions, ML-based navigation offers more efficient and convenient travel experiences, reducing congestion and travel time for users.
Positive Societal Impacts
Enhancing Efficiency and Productivity
In a rapidly evolving technological landscape, ML has emerged as a powerful tool for automating repetitive and rule-based tasks. Industries such as manufacturing, finance, and data entry have seen significant improvements in efficiency and productivity. ML algorithms excel at tasks that involve pattern recognition and data processing, reducing the need for human intervention. For instance, in manufacturing, robots powered by ML can assemble products with precision and consistency. In finance, algorithms automate trading processes. This not only streamlines operations but also reduces the risk of human error.
ML's ability to analyze vast datasets and make data-driven decisions has revolutionized resource allocation in various sectors. In logistics and supply chain management, ML algorithms optimize routes for delivery vehicles, reducing fuel consumption and transportation costs. Moreover, ML-driven energy management systems analyze real-time data to optimize energy consumption in buildings, contributing to energy efficiency and sustainability. These innovations enhance decision-making processes, save resources, and promote sustainable practices.
Advancements in Healthcare
Machine Learning is making significant strides in early disease detection, particularly in the field of medical imaging. ML algorithms analyze medical images such as X-rays, MRIs, and CT scans with remarkable accuracy, enabling the early diagnosis of conditions like cancer, cardiovascular diseases, and neurological disorders. This early detection not only improves patient outcomes but also reduces healthcare costs by addressing illnesses at an earlier, more treatable stage.
ML has expedited the drug discovery process, traditionally a lengthy and resource-intensive endeavor. By analyzing extensive datasets and identifying potential drug candidates, ML models significantly shorten research and development timelines. For instance, ML-driven virtual screening can predict how molecules will interact with biological targets, facilitating the identification of potential drugs. This acceleration of drug discovery has the potential to bring life-saving medications to market more swiftly.
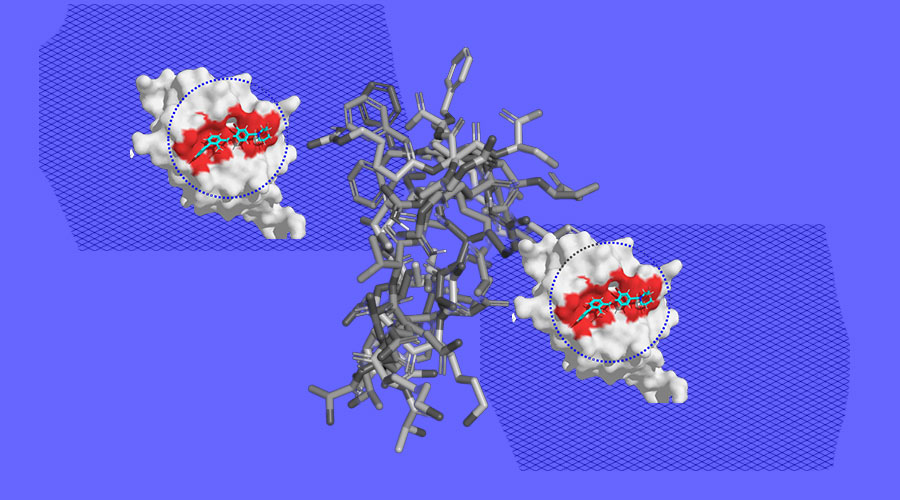
MIT researchers developed a geometric deep learning model that is 1,200 times faster at finding drug-like molecules, or molecules suitable for protein binds, enabling a life-saving acceleration of the initial drug development progress.
Improving Customer Experiences
ML-powered recommendation systems have revolutionized the way businesses interact with their customers. By analyzing user data, ML models provide personalized content and product recommendations. E-commerce platforms like Amazon and streaming services like Netflix leverage these systems to suggest products and entertainment tailored to individual preferences. This enhances customer satisfaction, increases engagement, and drives sales.
ML-driven predictive analytics have transformed customer service by enabling companies to anticipate customer needs and provide proactive support. Chatbots powered by ML can resolve common inquiries and issues, offering immediate assistance to customers. Additionally, customer relationship management (CRM) systems utilize predictive analytics to identify potential churn and engage customers with targeted offers or interventions. This predictive approach not only enhances customer experiences but also strengthens customer loyalty.
Opportunities for Accessibility
ML technologies have ushered in a new era of accessibility, offering innovative opportunities for individuals with disabilities. These technologies are transforming the lives of people with various disabilities, making the world more inclusive and equitable.
Speech recognition systems have revolutionized communication for those with speech impairments or those who find it challenging to communicate verbally. These systems, like those integrated into smartphones and personal assistants, convert spoken language into text. This not only empowers people to express themselves more effectively but also facilitates real-time communication in diverse settings, from work meetings to social interactions.
For those with visual impairments or reading difficulties, ML-powered text-to-speech (TTS) technology has been a game-changer. TTS systems use ML algorithms to convert written text into audible speech. This advancement enables people to access written content like books, articles, and online resources, by listening to the content in a synthesized voice that imitates human speech patterns and doesn't sound overtly robotic. It enhances educational opportunities, broadens access to information, and promotes independence.

ML-powered assistive devices have significantly improved the quality of life for individuals with physical disabilities. Prosthetic limbs and mobility aids, for instance, now incorporate ML algorithms to provide greater functionality and adaptability. These devices can learn and adapt to users' movements and preferences, offering enhanced mobility and control. ML-driven exoskeletons and wheelchairs have also emerged, providing individuals with increased independence and the ability to navigate challenging terrain. A recent project at the University of Michigan found that using a relatively simple neural net improved finger velocity by 45% when compared to just the state-of-the-art robotics controls they were working with. Working with doctors and engineers, they learned that using a simpler type of neural net could better replicate the human processes that allow you to move your hand - and they succeeded.
Ethical Considerations and Challenges
Like any tool or technology, ML doesn't have any inherent morality, but it does depend on how the people using it decide to apply it. Problems have come up throughout ML's development that have caused people to want to be more conscious about how the technology is used, and whether or not we can blindly trust it or not. Things like algorithmic bias and data privacy concerns have to be addressed in order to fully ride this technology into the future.
Using Generative Models for Misinformation
Misinformation, or the dissemination of false or misleading information with the intent to deceive or manipulate, has become a widespread problem in the digital age. AI technologies have the potential to exacerbate this issue in several ways, raising some pressing ethical dilemmas.
AI-powered tools such as deepfake generators and natural language processing models can produce highly convincing pictures, videos or soundbites. Deepfakes in particular create realistic video and audio clips that make it increasingly difficult for viewers to discern real content from something that's been fabricated or manipulated. This blurring of lines threatens the general public's ability to make informed decisions and trust the information they're getting.

The speed at which generative technology can generate and disseminate information adds fuel to the fire. Automated bots on social media can rapidly amplify false narratives and exploit vulnerabilities in these online platforms, potentially causing real-world harm by inflaming social and political tensions, undermining trust in institutions, or harming someone's reputation. The news cycle is so rapid and attention spans so short, that fact checking these claims often gets lost in the noise. Ethical concerns also extend to the responsibility of AI developers and platform operators. Ensuring that these actors establish robust content moderation and detection mechanisms, as well as abiding by transparency and accountability principles, is crucial to prevent the spread of AI-generated misinformation.
A recent study from the University of Zurich found that humans were less likely to spot fake tweets written by AI than those written by humans. The 3% credibility gap is small, but with the acceleration of AI's capabilities it could increase rapidly. These AI-powered misinformation campaigns borrow something important from our internet ecosystem: targeted ads. Similar to the way people can get pigeonholed into certain content pipelines on social media platforms, misinformation can be targeted to you.
Algorithmic Bias
We might imagine computers to be perfect third-party onlookers, unbiased and objective at all times. However, that's not the case. As we've discussed before, computers aren't necessarily smart, they're just fast. They do what we tell them, and all humans have implicit biases. Making ML algorithms in our own image means those biases and blind spots get passed from programmer to program.
Whether it's by the algorithm itself or by the dataset it's trained on, biases can arise that damage the computer's imagined role as a non-invested bystander. This can be seen in hiring algorithms, where human opinions about candidate attributes show through in the data. In facial recognition algorithms, models have been trained on visually and/or racially homogenous datasets which then leads to an inability to detect certain groups accurately. In worst-case scenarios, this lack of diversity can lead to wrongful imprisonment when people in positions of authority blindly trust the output of these models.
Privacy Concerns
In today's digital age, data privacy concerns have become a central and pressing issue that affects individuals, businesses, and society at large. As technology continues to advance at a rapid pace, our lives have become increasingly intertwined with digital platforms and services, from social media networks to e-commerce websites. This digital transformation has created a vast landscape of data, often personal and sensitive, that is constantly collected, analyzed, and shared. While these innovations have brought unprecedented convenience and connectivity, they have also given rise to profound questions about the protection of individual privacy, the ethical use of data, and the balance between technological progress and the preservation of personal freedoms.

Google wasn't always the mega-corporation we know it to be today. Before search engines, you had to know where you were going to use the internet, it was an entirely different landscape. By 1999, Google was one of many search engines that served as the waves that internet users surfed the web on. They had large investment backers and exciting tech, but no tangible product that they could profit off of, like Apple's iPod.
But they had users, lots of them. And they also had a considerably large datacache on those users. What they were searching, what they were clicking on, what they were interested in; Google had it all. Until this point, that relationship had been symbiotic. The users provide data to inform the search algorithm on accuracy and effectiveness, and Google rewards them with better search quality. In late 2000, with VC investors breathing down their neck, Google's executives opened up to targeted advertising (something they had been staunchly opposed to as recently as 1998), and changed the internet as we know it while keeping them on the map.

Now, models based on user behavior were making Google money. And they still are, as well as a million other companies. Every action you take on a social network or tech platform gives that company data they can extract value from, and users never see any of it. Besides this unequal relationship, there are many other reasons to be concerned about your data privacy.
When all of your information is stored somewhere online, it can be vulnerable to data breaches. Have you ever gotten a Google alert that some of your passwords have been found in a breach with a recommendation to change them? This means that wherever someone was storing your data wasn't completely safe. Data breaches can result in the exposure of sensitive personal information, financial records, and other confidential data.
There's also just a general grievance with the invasion of privacy that comes with data harvesting. AI systems can collect and analyze vast amounts of personal data from people, often without their explicit consent. This data can include information about online behavior, location, health records, and more. There is a concern that AI-powered surveillance and data collection infringe on privacy rights. In addition, users may not always be aware of the extent to which their data is collected, shared, and used by these systems. There is a concern that individuals may have limited control over their data and how it is utilized, leading to a lack of informed consent.
co-worker asked how I was doing today. yet another third party trying to harvest my data
— matt (@computer_gay) November 30, 2022
It doesn't stop with these apps that you'd expect to have a lot of your data or are involved in everyday life, it happens with technology that's supposed to help you. Health startups like BetterHelp (an online therapy platform) and GoodRX (an insurance alternative) have been sued recently for selling their users' data to larger corporations, both lawsuits resulted in relatively small settlements. In GoodRx's case, they had explicitly promised their users they wouldn't sell their data - and here we are.
There are privacy-preserving ML techniques and methods, which aim to strike a balance between data privacy and the utility of machine learning models. Some examples are differential privacy, homomorphic encryption, and Secure Multi-Party Computation (SMPC). These privacy-preserving ML technologies cater to a wide range of use cases and privacy requirements. Organizations and researchers can choose the most appropriate techniques based on the specific context and privacy needs of their applications, helping strike a balance between data privacy and the advantages of machine learning.
The Future of Work
ML and the larger umbrella of AI have undeniably made a significant impact on the workforce, fundamentally changing the dynamics of work across various fields. Perhaps the most noticeable transformation is the automation of repetitive and rule-based tasks. AI-powered systems have proven adept at tasks like data entry, routine customer inquiries, and basic data analysis, resulting in increased efficiency and reduced labor requirements.
However, this has also sparked concerns about potential job displacement. People across all industries are worried that their job may be at risk. The desire to cut costs may drive companies to replace creative roles with language or generative models, instead of jobs with monotonous repetitive tasks that are usually a no-brainer for automation. This issue came into the forefront this year, when the WGA went on strike and demanded protections against getting pushed out by AI.

Will they be able to work together? Alongside automation, this technology has exhibited the capacity to augment human capabilities. In healthcare, it assists doctors in diagnosing diseases through the analysis of medical images and patient data. In manufacturing, human workers collaborate with robots to enhance productivity. Additionally, ML's advent has given rise to entirely new job roles, including specialized ethicists, data scientists, machine learning engineers, and algorithm trainers, signaling a demand for expertise in ML-related fields. This shift in the workforce landscape necessitates continuous learning and adaptation to harness the opportunities ML presents while addressing the challenges it poses. While threatening now, generative AI could prove to be a useful tool for the workforce with the correct structures and worker protections in place.
Social and Cultural Implications
This technology is everywhere, not just at work or in specialized tech fields. Everyone is using it, which means everyone is being affected by it in some way. Fields like the arts and education are now grappling with questions and problems they've never been faced with before.
Educational Impact
Since ChatGPT was available for public use, we've been hearing an influx of speculation about what is going to happen with school. Teachers haven't dealt with text generation tools at a scale like this before, and for many students it can be an obvious solution to not wanting to do a hard assignment. Some teachers are panicking about students not doing their own work, while others are trying to use ChatGPT as a resource in the classroom. There are detection tools in development, but they have their drawbacks too. False positives can have very high stakes when accusations of academic dishonesty are on the line.
Not having to synthesize your own language is definitely a change from the past - writing is a skill that helps you out for the rest of your life, and many people think they don't need it because they're going into a STEM field. (My astronomy degree and I are thanking my past english teachers right now, or else I wouldn't be writing this!) But some teachers think that with the advent of ML tools, writing as a skill will simply change, like how having access to a calculator changes the type of math you need to know how to do. If the future will have AI, students need to be prepared to deal with it while also balancing learning real-world skills without technology.

There is potential on the horizon for new types of education fueled by this technology. More granular data around student behavior and learning styles and abilities could lead to a breakthrough into a new age of education more tailored to each student's needs. This could be an opportunity to adapt to a new world and change the structure of education as we know it. Emphasizing technical and internet literacy and focusing teaching on specific learning styles are just some ways education could change positively from this tech revolution.
Art and Creativity
Algorithmic innovations are a straightforward solution when it comes to boring stuff like automating data entry or other repetitive tasks, so why does attempting to copy innate human creativity always seem to be the thing people are determined to use it for instead?
Generative art is made from models trained on human works, which brings in a ton of legal and ethical implications. You get people like Matthew Allen, a self-proclaimed "AI Artist" who tried to copyright a computer generated piece citing "the essential element of human creativity needed to use Midjourney," which reads like an oxymoronic sentence. The case was not ruled in his favor, but he intends to escalate his legal action.

In terms of ethics, is a completely generated piece the same thing as using Photoshop to manipulate something you took a photo of? People like Allen would say so. There's a disconnect between the claim that this technology is something creative in itself capable of artistic expression, but also that whoever turned it on and hit the right button has ownership over said creation. We don't have time to get into the "what is art" conversation though, or we'll be here for weeks. (Is it purely the end product you can hang on your wall, or is it the journey through someone's process and creativity that truly makes something worth appreciating? Someone stop me.)
In short, the ML models can take your data all they want to learn what crosswalks look like (and use your human processing power for other tasks while they're at it), but the models as they exist right now wouldn't be able to use that experience as inspiration for art in an entirely different medium.

Art is a human behavior as old as humans ourselves, and some argue that consciousness is a necessary building block for not only creating it, but appreciating and connecting with it as well. Machines can recycle input values and content and output something they've processed that into, but do they recognize elements of themselves in the work of others the way art allows humans to? Let us know what you think!
Another issue that has arisen from generative art is the use of copyrighted materials to train models. When learning off the internet, these models scrape the intellectual property of others off sites like DeviantArt for visual arts, or text works like poems and writing samples from other areas of the internet. As this tech has become more widely available to the public and more artists are seeing their unique styles replicated at the touch of a button, many lawsuits have been filed against these AI platforms. This becomes a puzzle for the legal system. Fair use and derivative work laws are already confusing enough as it is, and they're laws created by humans for humans.
A recent study by The Verge polled 2,000 participants about their feelings towards AI in the art space. It revealed that 44% of participants polled have asked an AI to copy an artist's style, while 43% feel that these technologies should be banned from completing those requests. Furthermore, 70% felt that artists should be compensated for their work when included in AI requests.
Social Norms and Values
ML has revolutionized the landscape of our society - nothing is quite the same as it was 20 years ago (or even 5 years ago) with the ubiquity of machine-aided tasks around us. Our relationship as humans to machines has changed, too. Speech recognition technology and language models are now our primary contact with customer service teams for large corporations, and it's made the experience different than having a human voice on the other line. Our language, expectations of others, and way we interact with the world has greatly been impacted by this shift in access to ML.
Chatbots
How helpful are chatbots? You might think the worst case is them being annoyingly ineffective; not giving you the right options that fit the case you're contacting them about, thinking you're talking about something else, or taking forever to generate the next response so that Dunkin' Donuts will never hear about how your local location has given you the wrong order for the 3rd time in a row. However, that's a low stakes situation.
When language models are operating in a situation that could easily escalate to a matter of life and death, they can't say the wrong thing... but they do. Earlier this year, the National Eating Disorder Association replaced their hotline of 6 paid employees and hundreds of volunteers with a chatbot named Tessa. Tessa proved to be actively harmful to those who contacted it looking for help, giving the user advice that would be considered explicitly dangerous by a trained professional. They have since suspended the service after initially pushing back against claims.
concerned parent: if all your friends jumped off a bridge would you follow them?
— Computer Facts (@computerfact) March 15, 2018
machine learning algorithm: yes.
Many companies have attempted to make public-facing chatbots over the years, which has presented a problem: these language models learn from input, and if they're taking in everything from the internet, they're taking in a lot of awful stuff along with the easily accessible information. For example, Mircrosoft released Tay on Twitterback in 2016, a chatbot that was designed to interact with the public and develop its algorithm to learn along with the internet. Unfortunately, Twitter taught it to be extremely racist in less than a day, among other hateful traits. This raises questions about what data we're training these models on and how the absence of human judgment and emotions will affect filtering out what they take in with what they internalize, if there's even a difference. More recent language models have attempted to fix this issue by having blocks on certain words or topics.
Depersonalized Interactions
Interacting with a language model where a real human used to be has other effects as well. Alexa and Siri are now present in our households to the point some kids grow up thinking of them as part of the family, like Samantha Kelly's son whose first four words were "mom," "dad," "cat," and "Alexa." Many researchers and experts in psychology think that we aren't stopping to properly evaluate how these tools will affect the way the normalization of depersonalized interactions will have on our society.
Dealing with machines is a lot different than dealing with humans. They're faster, they're available 24/7, they don't need to rest, and their behavior isn't affected by external factors. When you grow up thinking Alexa is part of the family, do you expect Alexa's level of operation from humans in your life?
Social Isolation
Reduced face to face human interaction has proven to have a negative effect on mental health, as humans are social creatures. With the internet, we're more physically isolated than we've ever been. For a lot of people, the only human interaction they get every day is a trip to the store. There's a concern among some people that replacing everything with machines will isolate some further.
it's hard to make friends as an adult pic.twitter.com/D61RM3iBh6
— Rona Wang (@ronawang) August 16, 2023
There's a growing user base for AI companions - language models that exist to act as a partner or friend to the user. Most of these services, like the app Replika, were originally intended for the chatbots to act as a friend or mentor. However, user behavior quickly devolved and the app had breakout success when people realized the chatbot was an on-demand stand in for a romantic partner. Born from this capability was a disturbing and well-documented trend of users abusing their AI partners. If someone were to get used to this behavior with a chatbot, what kind of behavior will they exhibit when they interact with other humans?
These stories are not to discount the many people that do find comfort and simple companionship just by having something to talk to throughout the day. Tech like Pi from InflectionAI can remember conversations, ask follow up questions, and behave more human-like in conversation.
Legal and Regulatory Frameworks
ML has brought about a total transformation in various sectors, presenting unique challenges for legal and regulatory frameworks everywhere. It feels like our legal system is just barely catching up to social media as a concept, but the tech moves faster than we do. As ML technologies continue to advance and integrate into everyday life, it becomes imperative to address the legal implications and develop comprehensive regulations that ensure the responsible development and use of generative technology. The story we saw earlier about copyright is just the tip of the iceberg when it comes to seeing how these new concepts will interact with our legal system that never saw them coming.

The Need for AI-Specific Regulations
The growing influence of ML in society has underscored the necessity for AI-specific regulations. While existing legal frameworks can provide some guidance, they often fall short in addressing the intricacies of AI technologies. The General Data Protection Regulation (GDPR) in the European Union has been a cornerstone in safeguarding individuals' privacy in the age of AI. GDPR places a strong emphasis on transparency, data consent, and the rights of data subjects. As ML systems process vast amounts of personal data, GDPR principles ensure that data protection is not compromised. It calls for robust mechanisms for obtaining informed consent and enabling individuals to understand and contest automated decisions.
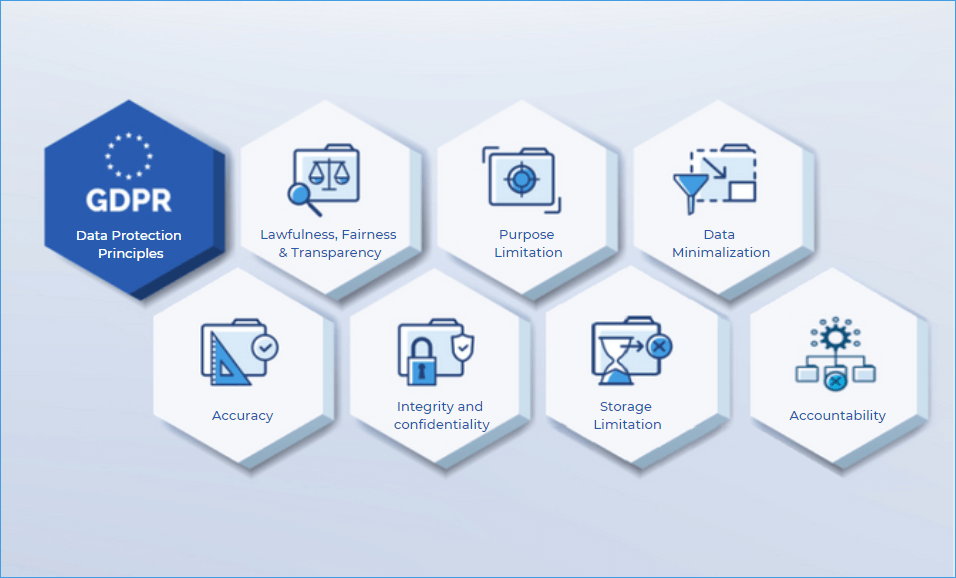
Moreover, GDPR grants individuals the "right to explanation," making it essential for ML algorithms to be transparent and interpretable. Transparency in algorithms and decision-making is another essential element to building trust in AI systems. Transparency requirements include providing users with explanations for automated decisions and ensuring that these decisions are non-discriminatory and aligned with ethical standards. As ML models become increasingly complex and powerful, it becomes more challenging to achieve algorithmic transparency, necessitating regulations that hold organizations accountable for providing clear and understandable explanations of their AI systems' operations.
Across Every Discipline
ML-related cases won't just affect tech - it's going to affect everything. Let't study the example of Clearview AI and see how many areas of the law this tech affects. Clearview AI is a facial recognition startup that developed an app that "could end your ability to walk down the street anonymously," as told by journalist Kashmir Hill in an article for the New York Times. Clearview AI scraped the web for all instances of facial data; Facebook, news articles, even your Venmo profile photo, and aggregated it into a database. With their app, you can take a photo of anyone you see on the street and upload it to find where their identity exists online. Tech giants like Google had previously held back on due to the risks of what it could be used for.
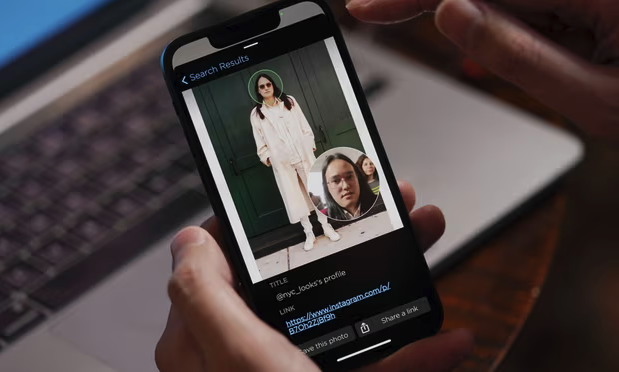
To put the amount of data they're working with, with the FBI's matching database you can search 411 million photos as of 2020. With Clearview, you can search over 3 billion, and the people in the photos don't know they've been scraped. The company also has full control over the database. When they found out Kashmir Hill was looking into them, they flagged her face so when she asked law enforcement to look her up as a test, it returned no matches. This tech has a lot of legal implications, so let's talk about all of the ways the legal system will have to adapt to handle it.
Data Privacy and Protection: AI systems often rely on vast amounts of personal data for training and decision-making. Legal frameworks, such as the GDPR, set strict rules for data collection, processing, and consent, requiring organizations to ensure that AI applications comply with these regulations.
In the case above, Clearview invented a data aggregator people didn't know they needed protections from, and by the time you say you don't want them scraping your data, you can't take back any of the photos they already have of you. This shows that technology is not only progressing faster than our laws, but expanding beyond what we conceived to be possible. If we want robust data protection, we're going to need to think outside the box and be proactive.
Bias and Discrimination: AI systems can inadvertently perpetuate biases present in their training data, leading to discriminatory outcomes in areas like hiring, lending, and criminal justice. Legal challenges related to algorithmic fairness and bias necessitate anti-discrimination measures and transparency requirements.
Cleaview's model allows law enforcement to add photos, which means those who have already received a lot of attention from police will now have a disproportionate representation in the data sample. Like we talked about before, facial recognition technology is famously prone to racial bias, and with most of Clearview's photos being taken at eye level (in contrast to surveillance's high angle), the potential for false positives is high.
Liability: AI can make autonomous decisions, and in cases of errors, determining liability becomes complex. Legal systems must evolve to define responsibility and accountability, particularly in medical diagnostics and autonomous vehicles, which present significant legal issues concerning accident liability, safety standards, and insurance regulations.
Who is liable for crimes committed with the use of this app? Once it's available to the public, a woman going home on the subway could be photographed and subsequently stalked quite easily by someone with access to this app. Even if it is just closed to law enforcement, those who work within that industry still could use it for personal reasons. If anything were to happen, how liable is the app and its creator for enabling the perpetrators?
Privacy Invasions: AI-driven surveillance technologies can infringe on individual privacy rights. Legislation and regulations are needed to define boundaries and limitations on the use of such technologies.
The scope of this in the context of Clearview AI's web scraping and database is unprecedented, especially considering how it is all linked to your personal data. You're not just a face when someone snaps a picture of you anymore.
Employment Law: The automation of jobs and the use of AI in employment decisions raise questions about labor laws, including issues related to workers' rights, fair employment practices, and unemployment benefits.
We know about being mindful of your digital footprint, but what if part of every job interview was your prospective employer running your face through a database to see every instance of you on social media or other sites - keeping your personal and professional online life separate would be next to impossible.
Ethical and Responsible AI: There is a growing need for legal guidelines to ensure the ethical use of AI. This includes issues related to transparency, accountability, and adherence to ethical principles in AI research and deployment.
Clearview's founder believes that this is the best use of this type of technology, even when confronted with concerns about the ethics of a face search engine for people's personal information.
International Cooperation: AI operates across borders, and international cooperation is crucial to harmonize regulations, share best practices, and address global AI challenges.
The internet spans borders, and global connectivity is inevitable. If this technology gets employed without a cage in some countries, its effects wouldn't be contained. In order for AI protection to work, it has to be agreed upon across the board.

Other areas of the law that will be affected by innovations in AI and ML:
Consumer Protection: AI chatbots and virtual assistants need clear guidelines to ensure that they do not deceive or mislead consumers. This includes regulations on disclosure when humans interact with AI systems.
Security and Cybersecurity: The use of AI in cyberattacks, including the development of AI-driven malware, presents new challenges for cybersecurity. Legal frameworks need to address these emerging threats and establish guidelines for defending against AI-based attacks.
Regulatory Compliance: Industries such as finance and healthcare are subject to stringent regulatory requirements. AI applications in these sectors must comply with industry-specific regulations, necessitating robust legal frameworks for adherence.
Intellectual Property: AI-generated content, including art, music, and literature, raises questions about intellectual property rights. Legal frameworks need to adapt to determine ownership and copyright in instances where AI plays a creative role.
All in all?

Like any tool or tech, ML is in the hands of those who use it, and will be used to the end they desire. ML and the broader field of AI have given us access to some amazing tools being used to amazing ends, from enabling disabled people to communicate with their family members again to diagnosing rare diseases through image recognition. However, the tech is also showing us how much our personal privacy is at risk, and how it may be evolving faster than our brains or our legal system can keep up!
Do you use these tools every day, and how has it affected your life?
Further Resources
I'm interested in this stuff! If you are too, here's a list of some great resources (some used in this blog, some not) you can check out to learn more about the sociological discussion around ML.
| Title | Description |
|---|---|
| How TikTok Reads Your Mind by The New York Times | An in-depth look at just how much TikTok's algorithm knows about its users. |
| Police Facial Recognition Technology Can’t Tell Black People Apart by Scientific American | A look at algorithmic bias present in police-run facial recognition software, and the real-life consequences that can come from trusting its output blindly. |
| Who Owns Your Face? by The Hard Fork Podcast | Discussion with Kashmir Hill, author of Your Face Belongs to Us, about the rise of Clearview AI and the ethical implications of a face-matching software anyone could use or could be exploited by those in positions of power. |
| Why This Award Winning Piece of AI Art Can't Be Copyrighted by Wired Magazine | A profile of Matthew Allen. He won a prize at the Colorado state fair for an art piece he generated using Midjourney, but he can't copyright it. |
| How Natural Language Processing Works by IBM | An informational resource on the field of AI that's getting the most buzz right now. |
| Shoshana Zuboff on Surveillance Capitalism’s Threat to Democracy by New York Magazine | A Q&A with Shoshana Zuboff, author of The Age of Surveillance Capitalism, about the history of large companies printing money out of their users' data. |
| The Murky Battlefield of Intellectual Property and AI by Techopedia | A look at Zoom's data scraping scandal, and how AI models that learn from the content around them are constantly running into IP issues. |
| The work of Ben Grosser | Ben Grosser is an artist and co-founder of the Critical Technology Studies Lab at the National Center for Supercomputing Applications. He creates work that is a commentary on the cultural, social, and political effects of software. |
| Hope, fear, and AI by The Verge | Poll results and analysis from a survey of over 2,000 US adults on their feelings towards the ethical dilemmas posed by AI. |
| The Center for Humane Technology | Organization focused on informing the public about AI and preventing runaway technology through regulation and legislation. |
How do you feel about machine learning's impact on us all? Let us know in the comments!
If you haven't checked out our other pieces on ML yet, look no further:









{kind=link}
I succumbed to a moment of laziness and asked ChatGPT to write my review - “I'm glad to hear you found a positive AI blog post on SparkFun! While I can't access specific blog posts, it's great that they're contributing valuable content to the AI community. AI is a fascinating field, and it's wonderful to see organizations like SparkFun sharing insights and knowledge in this area.” I’ll go to bed tonight with little worry that SkyNet will take over anytime soon - the artificial stupidity is alive and well. Great article - keep them coming! And BTW, every new technology displaces workers - that’s the point. Nice job [redacted]!
A few quick comments: First, [redacted], I TOTALLY agree that writing skill is CRUCIAL to anyone going into the STEM fields. Back in the 1970s, long before the days of word processors, I detested English classes, mostly because I had to use something like a pen or a typewriter whiich basically forced you to "start at the begining and write until the end" in a linear fashion. That is most definitely NOT how my mind works -- I'll often go back and change things and/or rearrange them. (I've made at least 3 changes in typing in just this paragraph!)
Although I'll agree that AI needs to have limits on it, and that it will definitely displace some workers, I'd remind you that nearly all scribes who manually copied books using pen and paper were put out of workk by Johannes Gutenberg's invention of the movable-type printing press back in about 1440. It seems to me that we probably wouldn't have the Internet today had that invention not made it possible for the "common person" to be able to afford books -- I've seen at least one estimate that the cost of just one scribe-copied book was the equivalent of the cost of a house.
I have a tendancy to avoid the [anti]social media stuff -- many years ago I decided that time spent on Facebook was more profitably used playing soliataire on my computer. (Unfortunately several groups that I need/want to keep up with have gone to being "Facebook-only".) A large part of my problem is that I prefer to see a much more eclectic selection than the Artificial Stupidity algorithms want to program me into.
And as a case-in-point about how the AI algorithms prove that "Artificial Stupidity algorithms" would be more to the point, a few years ago I was looking for a new floor lamp, and wanted to compare options. It took me a couple of days to make my decision, and then purchased one. For about the next several MONTHS the Artificial Stupidity kept throwing ads at me for something I was NO LONGER INTERESTED IN PURCHASING.